Скачать в формате PDF 
|
|---|
Рекомендация по настройке параметров оптимизации производительности устройств «С-Терра Шлюз 7000» и «С-Терра Шлюз 8000»
Данная рекомендация актуальна для двухпроцессорных аппаратных платформ (АП). Документ содержит настройки параметров оптимизации производительности для устройств «С-Терра Шлюз» 7000HE (на базе платформы Lanner FW-8894B с двумя процессорами «Intel Xeon 2643v4 3.40GHz») и двух версий устройств «С-Терра Шлюз» 8000HE (на базе платформы Lanner FW-8894B с двумя процессорами «Intel Xeon 2699v4 2.20GHz» и на базе платформы Aquarius T50 с двумя процессорами «Intel Xeon Gold 6226R 2.90GHz»). Если на вашей АП установлен иной процессор, то обратитесь в службу технической поддержки.
Настройки, описанные в рекомендации, актуальны для «С-Терра Шлюз», программное обеспечение которого не ниже BIM43_2020_11_17 и AGENT43_19_12_27__20279_B (версии ПО можно посмотреть при помощи команды cat /etc/image_version). В документе также описаны особенности настройки параметров оптимизации производительности для версии AGENT43_23_06_09__23955_B (4.3 FW). Рекомендованные параметры для АП «С-Терра Шлюз» 8000HE на базе платформы Aquarius T50 применимы только для ПО версии AGENT43_23_06_09__23955_B (4.3 FW). Если у Вас более старая версия, обратитесь в техническую поддержку за обновлением.
Настройки параметров оптимизации производительности применимы для аппаратных платформ «С-Терра Шлюз» 7000HE и «С-Терра Шлюз» 8000HE, которые, как правило, размещаются в центральных офисах и предоставляют защищенный доступ большому количеству филиальных шлюзов (или VPN клиентов) к ресурсам центрального офиса.
Сетевые карты Intel не могут корректно балансировать фрагментированный трафик по очередям, что приводит к снижению производительности, поэтому старайтесь избегать фрагментированного трафика.
На производительность АП могут влиять как общие параметры (применимые к обеим платформам/процессорам), так и частные параметры, которые необходимо настраивать в зависимости от модели АП/процессора и типа обрабатываемого трафика.
Необходимо убедиться в том, что Hyper-Threading и NUMA включены (на всех ПАК, поддерживающих данные технологии, они должны быть включены по умолчанию). Ниже представлено описание проверки общих настроек АП.
Hyper-Threading – это аппаратная технология, позволяющая обрабатывать на каждом ядре процессора несколько программных потоков (в случае отсутствия Hyper-Threading одно ядро процессора обрабатывает один программный поток). Чем больше программных потоков обрабатывается на одном ядре, тем больше задач может выполняться на нём параллельно. После включения технологии Hyper-Threading в рамках каждого физического ядра, будут созданы два логических ядра, которые могут обрабатывать разные программные потоки одновременно. Для того, чтобы посмотреть, включена ли технология Hyper-Threading на устройстве, необходимо воспользоваться командой lscpu и обратить внимание на поле «Thread(s) per core»:
root@Gate7000HE:~# lscpu
…
CPU(s): 24
On-line CPU(s) list: 0-23
…
Thread(s) per core: 2
Core(s) per socket: 6
…
Вывод утилиты приведён на АП «С-Терра Шлюз» 7000HE (полный вывод команды lscpu для каждой из АП можно найти в главе «Приложение»). Поле «Thread(s) per core» показывает, какое количество потоков может обрабатывать одно ядро. Если включена технология Hyper-Threading, то каждое ядро будет обрабатывать два потока параллельно. Поле «CPU(s)» показывает, сколько ядер доступно в операционной системе.
Если технология Hyper-Threading отключена, необходимо обратиться в техническую поддержку для получения инструкции по её включению.
NUMA (Non-Uniform Memory Access) – это аппаратная технология взаимодействия одного процессора с блоками памяти другого процессора. Технология NUMA способствует распределению процессов в системе таким образом, чтобы они получали области оперативной памяти, расположенные максимально близко к процессорам, на которых работают. Для АП «С-Терра Шлюз» 7000HE и «С-Терра Шлюз» 8000HE доступно разделение процессоров и памяти на два NUMA узла. Для того, чтобы посмотреть, включена ли технология NUMA на устройстве, необходимо воспользоваться командой lscpu (полный вывод команды lscpu для каждой из аппаратных платформ можно найти в главе «Приложение»):
root@Gate7000HE:~# lscpu
…
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
…
…
…
L2 cache: 256K
L3 cache: 20480K
NUMA node0 CPU(s): 0-5,12-17
NUMA node1 CPU(s): 6-11,18-23
…
Строка «NUMA node(s)» содержит количество NUMA узлов, доступных операционной системе. Вывод утилиты свидетельствует о том, что в системе доступны 2 NUMA узла (данная технология на устройстве включена). В первом NUMA узле находятся ядра с номерами: 0-5,12-17 (ядра процессора cpu0), во втором NUMA узле находятся ядра с номерами: 6-11,18-23 (ядра процессора cpu1).
Если технология NUMA отключена, необходимо обратиться в техническую поддержку для получения инструкции по её включению.
В процессорах Intel присутствует система управления производительностью P-State, которая предназначена для повышения энергоэффективности процессоров без заметного ухудшения производительности. Параметр min_perf_pct позволяет избегать переходных процессов и при поступлении больших объёмов трафика сразу задействует процессоры на максимальных частотах. По умолчанию, значение min_perf_pct для АП «С-Терра Шлюз» 7000HE и «С-Терра Шлюз» 8000HE должно быть равно 100. Для того, чтобы посмотреть, какое значение записано в файл min_perf_pct, необходимо воспользоваться командой:
root@Gate7000HE:~# cat /sys/devices/system/cpu/intel_pstate/min_perf_pct
100
Если в файл /sys/devices/system/cpu/intel_pstate/min_perf_pct записано другое значение, необходимо обратиться в техническую поддержку.
При использовании АП в режиме «шифрование» необходимо проверить параметр DefaultCryptoContextsPerIPSecSA в файле /opt/VPNagent/etc/agent.ini. Данный параметр определяет количество криптографических контекстов, создаваемых для одного IPsec SA в соответствии с данным правилом IPsecAction. Наличие нескольких контекстов позволяет параллельно обрабатывать пакеты с использованием одного IPsec SA. Однако создание дополнительных криптографических контекстов требует ресурсов и может привести к превышению ограничений в криптографических библиотеках.
Значение DefaultCryptoContextsPerIPSecSA должно превышать общее количество процессорных ядер на 1. Например, для АП «С-Терра Шлюз» 7000HE с количеством ядер (поле «CPU(s)») равным 24, вывод команды будет следующим:
root@Gate7000HE:~# cat /opt/VPNagent/etc/agent.ini | grep DefaultCryptoContextsPerIPSecSA
! of the DefaultCryptoContextsPerIPSecSA field. Value must be from 1
DefaultCryptoContextsPerIPSecSA = 25
Если в файл /opt/VPNagent/etc/agent.ini записано другое значение, необходимо изменить его вручную.
Для того, чтобы выставить корректное значение DefaultCryptoContextsPerIPSecSA, необходимо:
1. С помощью команды lscpu | grep CPU (поле «CPU(s)») узнать, сколько ядер доступно в операционной системе.
В файл /opt/VPNagent/etc/agent.ini записать в переменную DefaultCryptoContextsPerIPSecSA полученное количество ядер + 1 (в данном случае 25):
root@Gate7000HE:~# vim.tiny /opt/VPNagent/etc/agent.ini
[Local Policy]
! Local Security Policy IPsecRule structure has optional field named
! CryptoContextsPerIPSecSA defining number of cryptographic contexts
! opened for each IPSec SA built with the IPsecRule. If the field is
! not defined there, number of cryptographic contexts equals the value
! of the DefaultCryptoContextsPerIPSecSA field. Value must be from 1
! to 128.
DefaultCryptoContextsPerIPSecSA = 25
3. Пересчитать контрольную сумму файла с помощью утилиты integr_mgr calc:
root@Gate7000HE:~# integr_mgr calc -f /opt/VPNagent/etc/agent.ini
SUCCESS: Operation was successful.
4. Перезагрузить АП с помощью команды reboot.
Параметр cpu_distribution в файле /etc/modprobe.d/vpndrvr.conf отвечает за распределение ядер драйвера (vpndrv) Продукта, то есть за то, какое количество ядер драйвера будет отведено на обработку прерываний, а какое – на основную обработку пакетов (межсетевое экранирование, шифрование, маркирование и т.д.).
Для того, чтобы посмотреть распределение ядер драйвера Продукта в файле /etc/modprobe.d/vpndrvr.conf, необходимо воспользоваться командой:
root@Gate7000HE:~# cat /etc/modprobe.d/vpndrvr.conf | grep cpu
options vpndrvr cpu_distribution=*:2/*
Параметр cpu_distribution драйвера vpndrv (является модулем ядра Linux) имеет следующий формат:
*:<irq cores>/<working cores>
· <irq cores> позволяет указать количество (или же конкретные номера) процессорных ядер, выделенных на обработку прерываний от пакетов с сетевых интерфейсов;
· <working cores> позволяет указать количество (или же конкретные номера) процессорных ядер, выделенных на основную обработку пакетов (фильтрация, шифрование, маркирование и др.), и взаимосвязь между working cores и irq cores.
Вывод утилиты свидетельствует о том, что на обработку прерываний выделено два ядра, а на обработку пакетов драйвером Продукта выделены все остальные ядра, причём, применено такое распределение ко всем сетевым интерфейсам платформы. Параметр cpu_distribution всегда выставляется при прохождении инициализации Продукта, но может быть изменен вручную в конфигурационном файле /etc/modprobe.d/vpndrvr.conf.
Изменять параметр cpu_distribution без согласования с вендором – запрещено! Если параметр cpu_distribution в файле /etc/modprobe.d/vpndrvr.conf был изменён, то для применения настроек необходимо перезагрузить АП (перезагрузки драйвера vpndrv недостаточно).
В версии AGENT43_23_06_09__23955_B (4.3 FW) параметр cpu_distribution имеет возможность гибкой настройки, при которой вручную указываются номера конкретных ядер, выделенных на обработку прерываний и на основную обработку пакетов, а также взаимосвязь этих ядер друг с другом. Предположим, на ПАК «С-Терра Шлюз» 7000HE с двумя процессорами «Intel Xeon 2643v4 3.40GHz» выставлено следующее распределение:
root@Gate7000HE:~# vim.tiny /etc/modprobe.d/vpndrvr.conf
options vpndrvr cpu_distribution=*:#0,1,2,3/#8~0,9~1,10~2,11~3,12~0,13~1,14~2,15~3
Данное распределение означает, что на обработку прерываний будет выделено 4 ядра (0, 1, 2, 3), а на основную обработку пакетов будет выделено 8 ядер (8, 9, 10, 11, 12, 13, 14, 15). Причём, прерывания, обработанные на ядре под номером 0, будут отправляться на «рабочие» ядра 8 и 12, c 1 на 9 и 13, со 2 на 10 и 14, с 3 на 11 и 15 соответственно.
Необходимо следить за тем, чтобы ядра, на которых обрабатываются прерывания, и привязанные к ним ядра, на которых производится основная обработка, находились на одной NUMA-ноде (определить, на какой NUMA-ноде находятся ядра, можно при помощи команды lscpu | grep NUMA).
Для просмотра текущего значения cpu_distribution можно также воспользоваться командой:
root@ Gate7000HE:~# cat /sys/module/vpndrvr/parameters/cpu_distribution
*:#0,1,2,3/#8~0,9~1,10~2,11~3,12~0,13~1,14~2,15~3
Конкретные ядра, на которых выполняется основная обработка трафика (vpndrvr процесс), можно посмотреть при помощи команды ps -Af. Например, вывод утилиты для cpu_distribution на «С-Терра Шлюз» 7000HE с двумя процессорами «Intel Xeon 2643v4 3.40GHz», указанного выше, будет следующим:
root@Gate7000HE:~# ps -Af | grep vpndrv
root 483 2 0 Sep26 ? 01:07:32 [vpndrvr/8]
root 484 2 0 Sep26 ? 00:14:58 [vpndrvr/9]
root 485 2 0 Sep26 ? 01:07:20 [vpndrvr/10]
root 486 2 0 Sep26 ? 00:15:01 [vpndrvr/11]
root 487 2 0 Sep26 ? 00:16:36 [vpndrvr/12]
root 488 2 0 Sep26 ? 00:17:14 [vpndrvr/13]
root 489 2 0 Sep26 ? 00:19:05 [vpndrvr/14]
root 490 2 0 Sep26 ? 00:18:51 [vpndrvr/15]
Число N в [vpndrvr/N] показывает на каком ядре выполняется нитка драйвера (vpndrv). Видно, что драйвер занимает с 8 по 11 ядра на первом процессоре и с 12 по 15 ядра на втором процессоре (см. вывод lscpu выше). Также видно, что на первых четырех ядрах первого процессора отсутствуют нитки драйвера, то есть отсутствуют [vpndrvr/0] - [vpndrvr/3]. Так и должно быть, потому что код vpndrvr, который отвечает за обработку прерываний работает в контексте ядра linux в нитках ksoftirqd/0 - ksoftirqd/3.
Рекомендуемые настройки параметра cpu_distribution для каждой из АП (в зависимости от режима работы) можно найти в главе «Приложение».
Данная настройка должна выполняться независимо от модели АП и типа передаваемого трафика на всех физических сетевых интерфейсах ПАК, которые поддерживают возможность выставления очередей (узнать, поддерживает ли сетевая карта выставление очередей, можно в инструкции к сетевой карте, либо же фактически попытаться выставить произвольное количество очередей, - если заданное значение применится, значит сетевая карта поддерживает возможность выставления очередей). Конфигурирование количества очередей на сетевой карте является необходимым условием для правильной работы механизма распределения прерываний от очередей сетевой карты к ядрам процессора(ов) и оптимальной производительности аппаратных платформ. Остальные параметры, касающиеся режима «шифрование» (cpu_distribution, NUMA, Hyper-Threading), корректно настроены на стадии производства.
Для того, чтобы определить, какое количество очередей выставлено на сетевом интерфейсе eth13, необходимо воспользоваться командой:
root@Gate7000HE:~# ethtool –l eth13
Channel parameters for eth13:
Pre-set maximums:
RX: 0
TX: 0
Other: 1
Combined: 24
Current hardware settings:
RX: 0
TX: 0
Other: 1
Combined: 24
Вывод команды приведён на АП «С-Терра Шлюз» 7000HE c двумя процессорами «Intel Xeon e5-2643v». Параметр «Combined» в поле «Current hardware settings» свидетельствует о том, что на сетевом интерфейсе eth13 выставлено 24 очереди (количество очередей по умолчанию зависит от количества ядер процессоров и от модели сетевой карты).
Количество очередей, на которые сетевая карта будет раскладывать пакеты, должно быть равно количеству ядер, отведённых на обработку прерываний (irq cores) кодом драйвера Продукта. Код драйвера, отвечающий за обработку прерываний, работает в контексте ниток ksoftirqd/N ядра Linux.
Для того, чтобы количество очередей выставлялось автоматически, необходимо:
1. Создать файл (если отсутствует) /etc/rc.local.inc:
root@Gate7000HE:~# vim.tiny /etc/rc.local.inc
2. Поместить в файл /etc/rc.local.inc строки ниже, записав в переменную QNUM количество ядер <irq cores>, которое указано в параметре cpu_distribution (в данном случае, оно равно 2):
QNUM=2
for phys_iface in $(ls /sys/class/net | grep -P "^eth\d+$")
do
echo Setting combined queue to $QNUM on $phys_iface ...
ethtool -L $phys_iface combined $QNUM
done
3. Перезапустить сервис rc.local.service:
root@Gate7000HE:~# systemctl restart rc.local.service
Данный файл будет выполняться автоматически после загрузки ОС или же после перезагрузки сервиса rc.local.service.
4. Проверить количество очередей на всех физических интерфейсах:
root@Gate7000HE:~# ethtool –l eth13
Channel parameters for eth13:
Pre-set maximums:
RX: 0
TX: 0
Other: 1
Combined: 24
Current hardware settings:
RX: 0
TX: 0
Other: 1
Combined: 2
Вывод утилиты свидетельствует о том, что теперь количество очередей на сетевом интерфейсе равно 2.
Помимо выставления количества очередей на сетевой карте, пропускная способность также зависит от того, каким образом сетевая карта разбалансировала пакеты по очередям.
При большом количестве IPsec туннелей пакеты должны распределиться по очередям и, соответственно, по ядрам-обработчикам равномерно. Для определения загруженности ядер процессора необходимо воспользоваться командой cpupower monitor. Раздел «Mperf» содержит столбец «С0», который показывает степень загруженности ядра в данный момент времени. При равномерной балансировке трафика вывод команды watch cpupower monitor должен выглядеть подобным образом (вывод команды приведён на АП «С-Терра Шлюз» 7000HE на базе двух процессоров «Intel Xeon e5-2643v»):
root@Gate7000HE:~# watch cpupower monitor
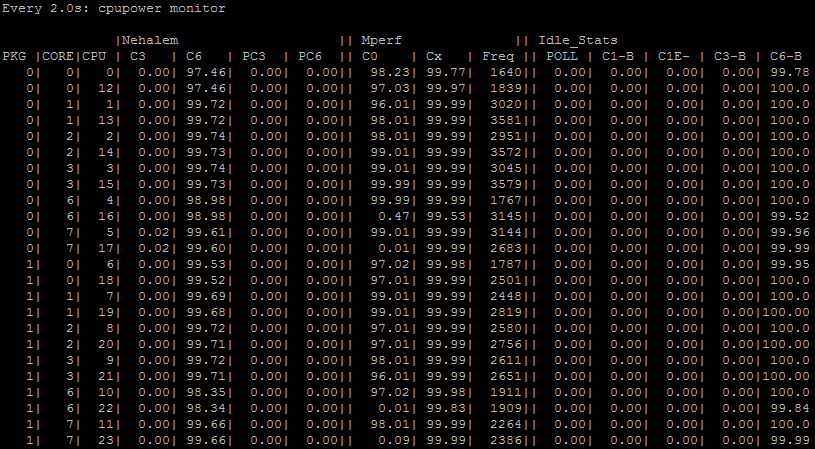
Рисунок 1. Загрузка ядер процессоров при равномерной балансировке трафика на АП «С-Терра Шлюз» 7000HE (2 x Intel Xeon e5-2643v 3.40GHz)
Столбец «CPU» содержит порядковые номера ядер в контексте операционной системы. Два логических ядра, входящих в одно физическое ядро, располагаются друг под другом (нулевому ядру соответствуют логические ядра 0 и 12, первому ядру соответствуют логические ядра 1 и 13 и так далее). Столбец «С0» свидетельствует о том, что ядра, которые отвечают за прерывания сетевых интерфейсов и IPsec шифрование, загружены почти на 100%. Загрузка распределена равномерно. Ядра под номерами 16, 17, 22 и 23 имеют практически нулевую загрузку из-за того, что не отвечают ни за прерывания, ни за шифрование. Аналогичный вывод будет на АП «С-Терра Шлюз» 8000HE с двумя процессорами «Intel Xeon Gold 6226R 2.90GHz», но загружены будут следующие ядра: 0-28.
Идентификаторы PCI-слотов, к которым подключены сетевые адаптеры можно посмотреть с помощью команды lspci -v | grep Ethernet.
Для просмотра информации о сетевом адаптере для платформы Lanner FW-8894B с двумя процессорами «Intel Xeon 2643v4 3.40GHz» и сетевыми адаптерами Intel 82599ES можно воспользоваться командой lspci -nnks 83:00.0. Вывод команды будет следующим:
root@Gate7000HE:~# lspci -nnks 83:00.0
83:00.0 Ethernet controller [0200]: Intel Corporation 82599ES 10-Gigabit SFI/SFP+ Network Connection [8086:10fb] (rev 01)
Kernel driver in use: ixgbe
Kernel modules: ixgbe
Для платформы Aquarius T50 с двумя процессорами «Intel Xeon Gold 6226R 2.90GHz» и сетевыми адаптерами Intel X710 необходимо воспользоваться командой lspci -nnks 5e:00.0. Вывод команды будет следующим:
root@Gate8000HE:~# lspci -nnks 5e:00.0
5e:00.0 Ethernet controller [0200]: Intel Corporation Ethernet Controller X710 for 10GbE SFP+ [8086:1572] (rev 02)
Subsystem: Silicom Ltd. Ethernet Controller X710 for 10GbE SFP+ [1374:0258]
Kernel driver in use: i40e
Kernel modules: i40e
Распределение пакетов по очередям можно посмотреть при помощи команды ethtool -S (регулярное выражение после grep может зависеть от версии драйвера сетевой карты). Например, на АП «С-Терра Шлюз» 7000HE для сетевого адаптера на базе Intel 82599ES (ixgbe) вывод будет следующим:
root@Gate7000HE:~# ethtool -S eth1 | grep "[rt]x_queue_[0-1]_packets"
tx_queue_0_packets: 7534
tx_queue_1_packets: 6978
rx_queue_0_packets: 8826
rx_queue_1_packets: 8333
В данном случае распределение пакетов по очередям равномерно. Так бывает не всегда и, как следствие, один из процессоров перегружается, а пропускная способность падает.
Помимо распределения пакетов по очередям, необходимо проверить, на каком ядре процессора обрабатываются пакеты из очереди. Например, на интерфейсе eth13 распределение будет следующим:
root@Gate7000HE:~# cat /proc/interrupts | grep eth13

Рисунок 2. Вывод информации о прерываниях сетевого интерфейса eth13 после выставления двух очередей на АП «С-Терра Шлюз» 7000HE (2 x Intel Xeon e5-2643v 3.40GHz)
Количество чисел в первом столбце (без учёта последней строки) равно количеству очередей, в которые сетевая карта будет раскладывать пакеты, попавшие на интерфейс eth13. В первом столбце располагаются номера прерываний (56, 57, 58). В строке, расположенной справа от номера прерывания, находятся числа, обозначающие количество пакетов, обработанных на конкретном ядре (нумерация ядер начинается с нуля). Рассмотрим прерывание 56. На шестом ядре обработано 6289 прерываний. Это значит, что прерывание 56 привязано к шестому ядру и обрабатываться будет на нём. Прерывание 57 привязано к нулевому ядру и на нём обработано 7123 пакета.
В случае использования АП «С-Терра Шлюз» 8000HE с двумя процессорами «Intel Xeon Gold 6226R 2.90GHz», вывод информации о прерываниях должен быть следующим:
root@Gate8000HE:~# cat /proc/interrupts | grep eth13

Рисунок 3. Вывод привязок прерываний сетевого интерфейса eth13 на АП «С-Терра Шлюз» 8000HE (2 x Intel Xeon 2699v4 2.20GHz)
Сетевая карта раскладывает пакеты, попавшие на интерфейс eth13, в две очереди. Номера прерываний данных очередей: 56 и 57 (номера прерываний после перезагрузки устройства могут меняться). Вывод консоли свидетельствует о том, что прерывание 56 привязано к четырнадцатому ядру, данное ядро является нулевым ядром NUMA node1. Прерывание 57 привязано к нулевому ядру, данное ядро является нулевым ядром NUMA node0. Таким образом, на АП «С-Терра Шлюз» 8000HE на базе платформы Lanner FW-8894B с двумя процессорами «Intel Xeon 2699v4 2.20GHz прерывания должны обрабатываться на ядрах 0 и 14.
За настройку привязок прерываний сетевых интерфейсов к ядрам на АП «С-Терра Шлюз» версии 4.3 отвечает сервис vpnirq. Данный сервис автоматически привязывает обработку прерываний сетевых интерфейсов к нулевому ядру NUMA node0 и к нулевому ядру NUMA node1. Если на сетевой карте выставлено две очереди стандартной настройкой, пакеты из первой очереди будут обрабатываться нулевым ядром NUMA node0, а пакеты из второй очереди нулевым ядром NUMA node1. Данные настройки значительно увеличивают эффективность обработки прерываний сетевых интерфейсов.
Если по каким-то причинам прерывания сетевого интерфейса привязаны к другим ядрам, перезапустите сервис vpnirq:
root@Gate7000HE:~# systemctl restart vpnirq
Приведенное выше описание сервиса vpnirq актуально только для «С-Терра Шлюз» версии 4.3. В версии AGENT43_23_06_09__23955_B (4.3 FW) за привязки прерываний сетевых интерфейсов теперь отвечает сервис vpndrv.
В случае расширенной настройки параметра распределения ядер драйвера Продукта (версия AGENT43_23_06_09__23955_B) необходимо убедиться, что пакеты обрабатываются именно на тех ядрах, которые были выставлены в файле /etc/modprobe.d/vpndrvr.conf, а количество очередей соответствует указанному количеству ядер, отвечающих за прерывания (irq) и значению QNUM, выставленному в файле /etc/rc.local.inc.
Если у пользователя небольшое количество IPsec туннелей, то сетевая карта не сможет автоматически разбалансировать по данным туннелям трафик. Одним из решений является ручная балансировка трафика по нескольким IPsec туннелям. С правилами настройки балансировки можно ознакомиться в главе «Ручная балансировка трафика по нескольким IPsec туннелям».
Если производительность АП не изменилась, необходимо искать причину, по которой так происходит. Для этого нужно обратиться к главам данного документа, представленным ниже.
Для повышения производительности необходимо, чтобы количество ядер, отвечающих за прерывания (irq), было равно количеству очередей (QNUM), выставленных на сетевой карте.
Предположим, АП «С-Терра Шлюз» 7000HE версии AGENT43_23_06_09__23955_B (4.3 FW) работает в режиме «шифрование». Наиболее высокопроизводительным вариантом будет следующее распределение ядер: 4 ядра драйвера Продукта выделено на обработку прерываний (irq) и 20 ядер на обработку пакетов (work), в данном случае, – шифрование:
root@Gate7000HE:~# cat /etc/modprobe.d/vpndrvr.conf | grep cpu_distribution
options vpndrvr cpu_distribution=*:#0,1,6,7/#2~0,3~1,4~0,5~1,12~0,13~1,14~0,15~1,16~0,17~1,8~6,9~7,10~6,11~7,18~6,19~7,20~6,21~7,22~6,23~7
Рекомендуемые настройки параметра cpu_distribution для каждой из АП можно найти в главе «Приложение».
Если параметр cpu_distribution в файле /etc/modprobe.d/vpndrvr.conf был изменён, то для применения настроек необходимо перезагрузить АП.
Параметр isolcpus актуален для версии 4.3 на «С-Терра Шлюз» 7000HE на базе платформы Lanner FW-8894B с двумя процессорами «Intel Xeon 2643v4 3.40GHz» и «С-Терра Шлюз» 8000HE на базе платформы Lanner FW-8894B с двумя процессорами «Intel Xeon 2699v4 2.20GHz».
Если ядра, на которых работает драйвер Продукта, загрузить сторонними системными процессами, то производительность АП может значительно снизиться. Параметр isolcpus позволяет выделить ядра, которые будут отвечать только за работу сервиса vpndrv (на сторонние процессы будут выделены другие ядра процессоров). Для того, чтобы посмотреть параметр в переменной isolcpus, необходимо воспользоваться командой:
root@Gate7000HE:~# cat /boot/grub/grub.cfg | grep isolcpus
linux /boot/vmlinuz-4.9.0-11-amd64 root=UUID=f902c305-b652-4be3-9ad3-f0d159135905 ro console=ttyS0,115200 console=tty crashkernel=1G-:256M ipv6.disable=1 net.ifnames=0 isolcpus=0-15,18-21 pti=off l1tf=off spectre_v2=off spec_store_bypass_disable=off nospectre_v1 nospec_store_bypass_disable nospectre_v2 nopti spectre_v2_user=off noibrs noibpb no_stf_barrier mds=off mitigations=off panic=300 quiet
На АП «С-Терра Шлюз» 7000HE (с двумя процессорами «Intel Xeon 2643v4 3.40GHz») параметр isolcpus должен содержать значения: 0-15,18-21:
root@Gate7000HE:~# cat /proc/cmdline | grep isolcpus
... isolcpus=0-15,18-21 ...
Также изолированные ядра можно посмотреть с помощью команды:
cat /sys/devices/system/cpu/isolated
На АП «С-Терра Шлюз» 8000HE (с двумя процессорами «Intel Xeon 2699v4 2.20GHz») параметр isolcpus должен содержать значения: 0-28:
root@Gate8000HE:~# cat /proc/cmdline | grep isolcpus
... isolcpus=0-28 ...
Если параметр isolcpus содержит другие значения, необходимо обратиться в техническую поддержку для получения инструкции по настройке данного параметра.
Для работы с трафиком уровня L2 на аппаратных платформах предусмотрен сервис l2svc. Логика работы следующая: на сетевой интерфейс платформы поступают L2-фреймы, далее, они инкапсулируются в UDP и IP при помощи сервиса l2svc, а, затем, шифруются средствами драйвера Продукта (vpndrv).
В режиме «шифрование на уровне L2» также необходимо, чтобы количество ядер, отвечающих за прерывания (irq), было равно количеству очередей (QNUM), выставленных на сетевой карте. Рекомендуемые параметры cpu_distribution для АП «С-Терра Шлюз» 7000HE и АП «С-Терра Шлюз» 8000HE, а также содержимое файлов конфигурации для каждой платформы представлены в разделе «Приложение».
Файл global.cfg позволяет выставить количество ядер, которое будет отведено под l2svc сервис. Для этого необходимо привести его к следующему виду:
root@Gate7000HE:~# vim.tiny /opt/l2svc/etc/global.cfg
...
L2VPN_CORE_COUNT="4"
BOND_MODE="balance-xor"
...
· «L2_VPN_CORE_COUNT» – задает количество ядер для работы l2svc процессов;
· «BOND_MODE» – задает режим балансировки трафика между tap-интерфейсами, объединенными в bond
Параметр L2_VPN_CORE_COUNT задает число последних ядер в системе, на которых будут выполняться процессы l2svc. По умолчанию (L2VPN_CORE_COUNT=1) все процессы l2svc выполняются на ядре с максимальным номером в системе (см. вывод команды lscpu). Например, если в системе 64 ядра, то при L2VPN_CORE_COUNT=4, процессам l2svc будут доступны ядра с номерами 60, 61, 62, 63. Выбор ядра для выполнения процесса l2svc происходит по алгоритму кругового цикла (round-robin), соответственно, количество конфигурационных файлов может превышать количество отведенных ядер для выполнения l2svc.
Сервис l2svc позволяет привязать работу определенного туннельного интерфейса (tap-интерфейса) к определенному ядру при помощи параметра bind_to_core_id <CORE> в конфигурационном файле туннельного интерфейса:
root@Gate7000HE:~# cat /opt/l2svc/etc/tap1.conf
vif tap1
local 1.1.1.1
remote 1.1.1.2
port 50000
bridge br0
capture eth2
mssfix 1400
passtos
bind_to_core_id 0
bonding bond0
· bind_to_core_id 0 – туннельный интерфейс tap1 будет работать на ядре под номером 0;
Данный параметр переопределяет глобальный параметр L2VPN_CORE_COUNT в файле /opt/l2svc/etc/global.cfg. В качестве ядра <CORE> может быть задано любое доступное в системе ядро. Параметр используется в случае, если определенным l2 туннелям нужно гарантировать пропускную способность за счет назначения выделенного ядра для исполнения l2svc.
Если настройка распределения ядер для работы туннельных интерфейсов производится через конфигурационные файлы /opt/l2svc/etc/tap*.conf и через глобальный файл конфигурации /opt/l2svc/etc/global.cfg, то наибольший приоритет будут иметь настройки, произведенные в файлах /opt/l2svc/etc/tap.conf. То есть, если в файле /opt/l2svc/etc/global.cfg параметр L2_VPN_CORE_COUNT будет равен 4, а в настройках четырёх туннельных интерфейсов будут привязки, например, к 0, 1, 2 и 3 ядрам, то сервис l2svc будет использовать для работы туннельных интерфейсов именно ядра 0, 1, 2 и 3 (по умолчанию сервис l2svc считывает значение параметра L2_VPN_CORE_COUNT и занимает заданное в нём количество ядер, начиная с последнего ядра второй NUMA-ноды в обратом порядке – последнее, предпоследнее и т.д.).
Содержимое файлов global.cfg для каждого из устройств приведено в главе «Приложение».
Помимо выставления количества ядер для работы с l2svc сервисом, необходимо задать нужный размер буферов для приёма и отправки пакетов. Для того, чтобы настроить размеры буферов, необходимо в файле /etc/sysctl.conf после строки «# buffer sizes» изменить текущие значения на следующие:
root@Gate7000HE:~# vim.tiny /etc/sysctl.conf
# buffer sizes
net.core.rmem_max=4194304
net.core.wmem_max=4194304
net.core.rmem_default=229376
net.core.wmem_default=229376
Для того, чтобы применить настройки, необходимо воспользоваться командой:
root@Gate7000HE:~# sysctl -p
Также, при конфигурировании туннельных интерфейсов в конфигурационный файл виртуального интерфейса необходимо добавить следующие строки:
root@Gate7000HE:~# vim.tiny /opt/l2svc/etc/tap0.conf
...
rcvbuf 1048576
sndbuf 1048576
...
· «rcvbuf» – размер буфера отправки пакетов на данном tap-интерфейсе;
· «sndbuf» – размер буфера приёма пакетов на данном tap-интерфейсе;
При использовании аппаратных платформ в топологии «точка-точка» в режиме «шифрование на уровне L2» рекомендуется объединять туннельные интерфейсы в bonding-интерфейс. Bonding-интерфейс является балансировщиком, который позволяет равномерно распределять сетевые пакеты по туннельным интерфейсам. Рекомендуется использовать bonding-интерфейс в режиме balance-xor.
Будьте внимательны, в режиме balance-xor при вычислении хеша от MAC-адреса учитывается только последний (младший) байт MAC-адреса. Если он в двух пакетах от разных устройств будет одинаковым, то пакеты не будут разбалансированы по туннельным интерфейсам, что приведёт к некорректной балансировке трафика по процессорам АП.
Также рекомендуется использовать такое количество туннельных интерфейсов, которое будет кратно значению параметра L2_VPN_CORE_COUNT (например, для АП «С-Терра Шлюз» 7000HE это значение рекомендуется выставить равным 4). При этом, рекомендуется использовать такое количество оконечных устройств, которое будет в 2 раза больше количества туннельных интерфейсов. Чем больше количество оконечных устройств относительно количества туннельных интерфейсов, тем более равномерно сетевые пакеты будут распределяться по ним.
В режиме «шифрование на уровне L2» распределение ядер зависит от модели платформы.
Предположим, АП «С-Терра Шлюз» 7000HE работает в режиме «шифрование на уровне L2». Наиболее высокопроизводительным вариантом будет следующее распределение ядер: 4 на обработку прерываний (irq), 16 ядер на основную обработку пакетов (work), 4 ядра на работу сервиса l2svc.
Таким образом, распределение ядер будет следующим:
root@Gate7000HE:~# cat /etc/modprobe.d/vpndrvr.conf | grep cpu_distribution
options vpndrvr cpu_distribution=*:#0,1,6,7/#2~0,3~1,4~0,5~1,12~0,13~1,14~0,15~1,8~6,9~7,10~6,11~7,18~6,19~7,20~6,21~7
Привязки туннельных интерфейсов сервиса l2svc к ядрам будут следующими:
root@Gate7000HE:~# cat /opt/l2svc/etc/tap* | grep bind
bind_to_core_id 16
bind_to_core_id 17
bind_to_core_id 22
bind_to_core_id 23
Если на АП «С-Терра Шлюз» 8000HE на базе платформы Lanner FW-8894B с двумя процессорами «Intel Xeon 2699v4 2.20GHz» запущено два l2svc процесса и, при этом, работает сервис vpndrv, то вывод команды watch cpupower monitor будет следующим:
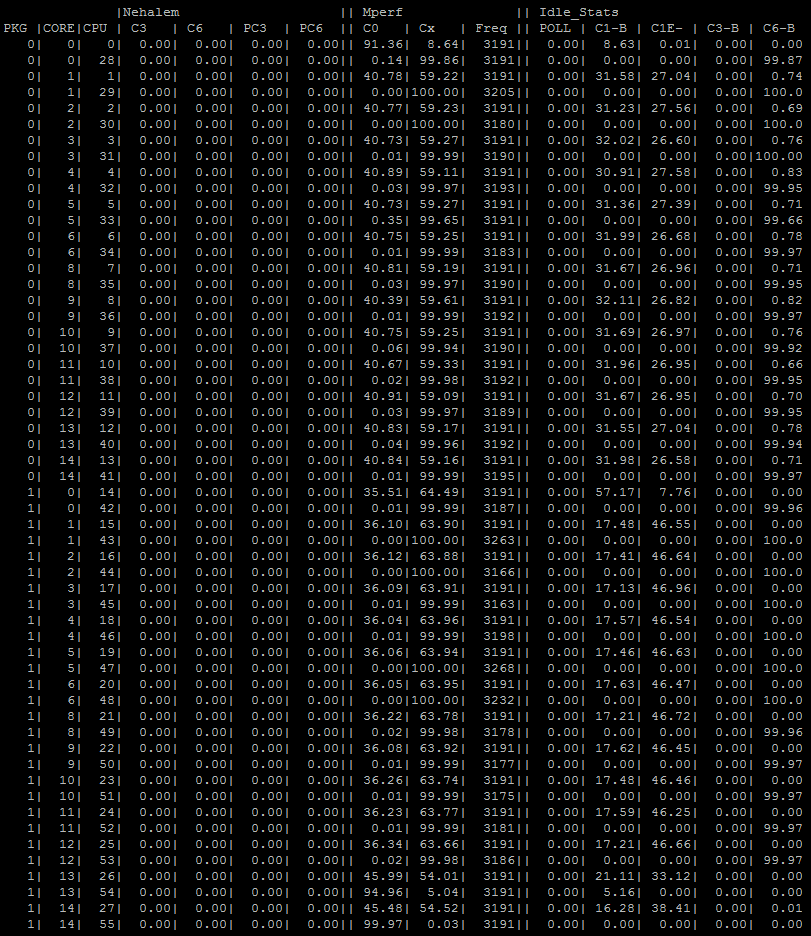
Рисунок 5. Загрузка ядер процессоров при работе в режиме «шифрование на уровне L2» трафиком на АП «С-Терра Шлюз» 8000HE (2 x Intel Xeon Gold 6226R 2.90GHz)
По умолчанию, ядра, на которых запущен l2svc процесс, занимаются с конца (если не задана ручная привязка в файлах конфигурации с помощью bind_to_core_id), а ядра, на которых запущен vpndrvr процесс, занимаются с начала списка ядер в выводе команды watch cpupower monitor.
Для АП «С-Терра Шлюз» 8000HE один l2svc процесс займет ядро под номером 55, два l2svc процесса займут ядра под номерами 55 и 54 и так далее.
Предположим, что на АП «С-Терра Шлюз» 7000HE версии 4.3 FW настроена привязка туннельных интерфейсов сервиса l2svc к последним ядрам NUMA node0 и NUMA node1 соответственно. Вывод команды watch cpupower monitor будет следующим:
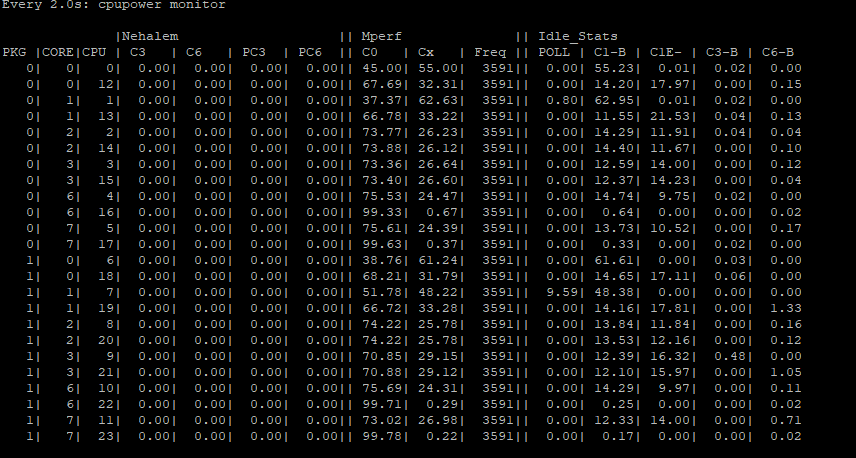
Рисунок 6. Загрузка ядер процессоров при работе в режиме «шифрование на уровне L2» на АП «С-Терра Шлюз» 7000HE с привязкой туннельных интерфейсов на последние ядра NUMA node
Ядра, на которых работают туннельные интерфейсы (16,17,22,23), загружены практически по максимуму. Ядра, которые отвечают за обработку прерываний от сетевых интерфейсов, загружены на 40-50%, а ядра, отвечающие за обработку пакетов, загружены примерно на 75%. Загрузка распределена равномерно.
В текущем режиме работы используется исключительно версия AGENT43_23_06_09__23955_B (4.3 FW). В режиме «межсетевое экранирование» также необходимо, чтобы количество ядер, отвечающих за прерывания (irq), было равно количеству очередей (QNUM), выставленных на сетевой карте.
Соответствующие настройки для ПАК «С-Терра Шлюз» 7000HE и «С-Терра Шлюз» 8000HE можно найти в главе «Приложение».
Наиболее высокопроизводительным вариантом для АП «С-Терра Шлюз» 7000HE будет следующее распределение ядер: 12 ядер на обработку прерываний (irq) и 12 ядер на основную обработку пакетов.
root@Gate7000HE:~# cat /etc/modprobe.d/vpndrvr.conf | grep cpu_distribution
options vpndrvr cpu_distribution=*:#0,1,2,3,4,5,6,7,8,9,10,11/#12~0,13~1,14~2,15~3,16~4,17~5,18~6,19~7,20~8,21~9,22~10,23~11
При работе АП «С-Терра Шлюз» 7000HE в режиме «межсетевое экранирование» существуют ограничения по количеству записей в расширенном списке доступа. Для версии AGENT43_23_06_09__23955_B (4.3 FW) 50 000 является максимальным количеством правил, при котором не наблюдается ухудшение производительности, при условии, что общее количество сессий не превышает 55 000. Стоит обратить внимание, что пакеты должны быть равномерно распределены по спискам доступа.
Предположим, что на АП «С-Терра Шлюз» 7000HE настроена stateless-фильтрация. Ниже представлен пример настройки расширенных списков доступа для трафика для LAN и WAN интерфейсов. Для каждого списка доступа описаны 50 000 комбинаций ip адресов, с портами источника и приемника.
ip access-list extended FW1
permit udp host 1.1.0.0 eq 1024 host 2.2.0.0 eq 1024
permit udp host 1.1.0.1 eq 1024 host 2.2.0.1 eq 1024
permit udp host 1.1.0.2 eq 1024 host 2.2.0.2 eq 1024
...
permit udp host 1.1.3.254 eq 1073 host 2.2.3.254 eq 1024
permit udp host 1.1.3.255 eq 1073 host 2.2.3.255 eq 1024
ip access-list extended FW2
permit udp host 2.2.0.0 eq 1024 host 1.1.0.0 eq 1024
permit udp host 2.2.0.1 eq 1024 host 1.1.0.1 eq 1024
permit udp host 2.2.0.2 eq 1024 host 1.1.0.2 eq 1024
...
permit udp host 2.2.3.254 eq 1024 host 1.1.3.254 eq 1073
permit udp host 2.2.3.255
eq 1024 host 1.1.3.255 eq 1073
В некоторых случаях сетевая карта может неравномерно распределить поступающие пакеты по очередям (подробную информацию о распределении пакетов по очередям сетевой карты можно найти в главе «Проверка результатов оптимизации производительности АП»). Для равномерного распределения пакетов по очередям можно применить ручную балансировку трафика.
Для балансировки поступающего трафика необходимо воспользоваться командой ethtool.
В файл /etc/rc.local.inc (с его содержимым можно ознакомиться в главе «Конфигурирование количества очередей на сетевой карте»), помимо выставления двух очередей на интерфейсах, необходимо добавить строки с командами ethtool --config-ntuple <...>. Так, например, если LAN-интерфейс – это eth13 и поступающие на него пакеты имеют destination-адреса 10.1.1.1 и 10.2.2.1, а WAN-интерфейс – это eth1 и поступающие на него пакеты имеют destination-адреса 192.168.2.127 и 192.168.2.128, то файл /etc/rc.local.inc должен иметь вид:
wan_if=eth1
lan_if=eth13
QNUM=2
for phys_iface in $(ls /sys/class/net | grep -P "^eth\d+$")
do
echo Setting combined queue to $QNUM on $phys_iface ...
ethtool -L $phys_iface combined $QNUM
done
ethtool -K $wan_if ntuple on
ethtool -K $lan_if ntuple on
ethtool --config-ntuple $wan_if flow-type ip4 dst-ip 192.168.2.127 action 0 loc 100
ethtool --config-ntuple $wan_if flow-type ip4 dst-ip 192.168.2.128 action 1 loc 101
ethtool --config-ntuple $lan_if flow-type ip4 dst-ip 10.1.1.1 action 0 loc 102
ethtool --config-ntuple $lan_if flow-type ip4 dst-ip 10.2.2.1 action 1 loc 103
· «action 0» – очередь под номером 0;
· «ip4» – название протокола;
· «loc 100» – номер правила на интерфейсе.
Пакеты, поступающие на интерфейс eth13 (LAN-интерфейс) и имеющие destination-адрес 10.1.1.1, будут отправлены в нулевую очередь, а пакеты, имеющие destination-адрес 10.2.2.1, будут отправлены в первую очередь. Аналогичная настройка происходит на интерфейсе eth13. Пакеты также можно балансировать при помощи source адресов (src-ip).
Подробнее ознакомиться с правилами распределения пакетов при помощи команды ethtool можно, используя мануал: man ethtool
Для просмотра настроенных правил для очередей на интерфейсе можно воспользоваться командой:
root@Gate7000HE:~# ethtool -n eth13
2 RX rings available
Total 2 rules
Filter: 100
Rule Type: Raw IPv4
Src IP addr: 0.0.0.0 mask: 255.255.255.255
Dest IP addr: 10.1.1.1 mask: 0.0.0.0
TOS: 0x0 mask: 0xff
Protocol: 0 mask: 0xff
L4 bytes: 0x0 mask: 0xffffffff
Action: Direct to queue 0
Filter: 101
Rule Type: Raw IPv4
Src IP addr: 0.0.0.0 mask: 255.255.255.255
Dest IP addr: 10.2.2.1 mask: 0.0.0.0
TOS: 0x0 mask: 0xff
Protocol: 0 mask: 0xff
L4 bytes: 0x0 mask: 0xffffffff
Action: Direct to queue 1
Для удаления правила необходимо воспользоваться командой:
root@Gate7000HE:~# ethtool -N eth13 delete 100
После балансировки трафика необходимо отследить загруженность ядер, распределение пакетов по очередям и ядрам. Загрузка должна быть равномерной.
Параметр pq_wait_cycles задает количество холостых попыток рабочих потоков драйвера Продукта для ожидания получения сетевого пакета перед тем, как этот поток «уснёт». Так как холостые попытки потребляют процессорное время, то в том случае, если через драйвер Продукта проходит небольшой объем сетевого трафика, - полезная производительность ядра, на котором выполняется рабочий поток, будет расходоваться на холостые попытки. Именно этим и обусловлены неточные показания загрузки ядер процессора при малых и средних объемах трафика.
Если значение pq_wait_cycles выставить в 1, то количество холостых попыток будет равно 1 и, следовательно, загруженность ядер процессора будет отображаться верно. Но, если трафик, проходящий через драйвер Продукта, имеет неравномерный характер, то производительность драйвера может снизиться. Это происходит в силу того, что в один момент времени может прийти большое количество сетевых пакетов, а часть рабочих потоков «спят» и требуется некоторое время на их «пробуждение». Из-за эффекта «пробуждения» рабочих потоков увеличится время обработки пакетов и, возможно, будут потери пакетов.
Значение pq_wait_cycles может быть подобрано опытным путем при одинаковых условиях эксперимента (тип трафика). Нужно отдавать предпочтение такому значению параметра pq_wait_cycles, при котором у вас наименьшее количество следующих ошибок в kstat_show:
· tx errors
· send queue overflows:
· high priority packets dropped
· low priority packets dropped
Суммарное значение данных ошибок не должно превышать 0.1% от общего трафика.
Если необходимо получать более точную информацию по загрузке ядер, то временно воспользуйтесь командой:
root@Gate7000HE:~# drv_mgr set pq_wait_cycles 1
Для того, чтобы посмотреть текущую настройку данного параметра, необходимо воспользоваться командой:
root@Gate7000HE:~# drv_mgr show | grep pq_wait_cycles
pq_wait_cycles 1
Без согласования с вендором менять значение параметра pq_wait_cycles не рекомендуется.
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 24
On-line CPU(s) list: 0-23
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2643 v4 @ 3.40GHz
Stepping: 1
CPU MHz: 1861.450
CPU max MHz: 3700.0000
CPU min MHz: 1200.0000
BogoMIPS: 6784.43
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 20480K
NUMA node0 CPU(s): 0-5,12-17
NUMA node1 CPU(s): 6-11,18-23
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb invpcid_single ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdseed adx smap intel_pt xsaveopt cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts
cat /etc/modprobe.d/vpndrvr.conf | grep cpu_distribution
options vpndrvr cpu_distribution=*:2/18
cat /etc/rc.local.inc
QNUM=2
for phys_iface in $(ls /sys/class/net | grep -P "^eth\d+$")
do
echo Setting combined queue to $QNUM on $phys_iface ...
ethtool -L $phys_iface combined $QNUM
done
cat /etc/modprobe.d/vpndrvr.conf | grep cpu_distribution
options vpndrvr cpu_distribution=*:#0,1,6,7/#2~0,3~1,4~0,5~1,12~0,13~1,14~0,15~1,16~0,17~1,8~6,9~7,10~6,11~7,18~6,19~7,20~6,21~7,22~6,23~7
cat /etc/rc.local.inc
QNUM=4
for phys_iface in $(ls /sys/class/net | grep -P "^eth\d+$")
do
echo Setting combined queue to $QNUM on $phys_iface ...
ethtool -L $phys_iface combined $QNUM
done
cat /etc/modprobe.d/vpndrvr.conf | grep cpu_distribution
options vpndrvr cpu_distribution=*:2/18
cat /etc/rc.local.inc
QNUM=2
for phys_iface in $(ls /sys/class/net | grep -P "^eth\d+$")
do
echo Setting combined queue to $QNUM on $phys_iface ...
ethtool -L $phys_iface combined $QNUM
done
options vpndrvr cpu_distribution=*:#0,1,6,7/#2~0,3~1,4~0,5~1,12~0,13~1,14~0,15~1,8~6,9~7,10~6,11~7,18~6,19~7,20~6,21~7
cat /etc/rc.local.inc
QNUM=4
for phys_iface in $(ls /sys/class/net | grep -P "^eth\d+$")
do
echo Setting combined queue to $QNUM on $phys_iface ...
ethtool -L $phys_iface combined $QNUM
done
cat /opt/l2svc/etc/tap* | grep bind
bind_to_core_id 16
bind_to_core_id 17
bind_to_core_id 22
bind_to_core_id 23
cat /opt/l2svc/etc/global.cfg
...
L2VPN_CORE_COUNT="4"
BOND_MODE="balance-xor"
BOND_MIIMON="100"
BOND_XMIT_HASH_POLICY="layer2+3"
cat /etc/modprobe.d/vpndrvr.conf | grep cpu_distribution
options vpndrvr cpu_distribution=*:#0,1,2,3,4,5,6,7,8,9,10,11/#12~0,13~1,14~2,15~3,16~4,17~5,18~6,19~7,20~8,21~9,22~10,23~11
cat /etc/rc.local.inc
QNUM=12
for phys_iface in $(ls /sys/class/net | grep -P "^eth\d+$")
do
echo Setting combined queue to $QNUM on $phys_iface ...
ethtool -L $phys_iface combined $QNUM
done
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 56
On-line CPU(s) list: 0-55
Thread(s) per core: 2
Core(s) per socket: 14
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2690 v4 @ 2.60GHz
Stepping: 1
CPU MHz: 1545.971
CPU max MHz: 3500.0000
CPU min MHz: 1200.0000
BogoMIPS: 5187.95
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 35840K
NUMA node0 CPU(s): 0-13,28-41
NUMA node1 CPU(s): 14-27,42-55
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb invpcid_single ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdseed adx smap intel_pt xsaveopt cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts
cat /etc/modprobe.d/vpndrvr.conf | grep cpu_distribution
options vpndrvr cpu_distribution=*:2/26
cat /etc/rc.local.inc
QNUM=2
for phys_iface in $(ls /sys/class/net | grep -P "^eth\d+$")
do
echo Setting combined queue to $QNUM on $phys_iface ...
ethtool -L $phys_iface combined $QNUM
done
cat /etc/modprobe.d/vpndrvr.conf | grep cpu_distribution
options vpndrvr cpu_distribution=*:2/26
cat /etc/rc.local.inc
QNUM=2
for phys_iface in $(ls /sys/class/net | grep -P "^eth\d+$")
do
echo Setting combined queue to $QNUM on $phys_iface ...
ethtool -L $phys_iface combined $QNUM
done
cat /opt/l2svc/etc/global.cfg
...
L2VPN_CORE_COUNT="28"
BOND_MODE="balance-xor"
BOND_MIIMON="100"
BOND_XMIT_HASH_POLICY="layer2+3"
...
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Vendor ID: GenuineIntel
BIOS Vendor ID: Intel(R) Corporation
Model name: Intel(R) Xeon(R) Gold 6226R CPU @ 2.90GHz
BIOS Model name: Intel(R) Xeon(R) Gold 6226R CPU @ 2.90GHz CPU @ 2.9GHz
BIOS CPU family: 179
CPU family: 6
Model: 85
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 2
Stepping: 7
CPU(s) scaling MHz: 32%
CPU max MHz: 3900.0000
CPU min MHz: 1200.0000
BogoMIPS: 5800.00
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon
pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe
popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_s
hadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx51
2bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req pku ospke avx512_vnni
md_clear flush_l1d arch_capabilities
cat /etc/modprobe.d/vpndrvr.conf | grep cpu_distribution
options vpndrvr cpu_distribution=*:#0,1,2,3,4,5,6,7,16,17,18,19,20,21,22,23/#8~0,9~1,10~2,11~3,12~4,13~5,14~6,15~7,32~0,33~1,34~2,35~3,36~4,37~5,38~6,39~7,40~0,41~1,42~2,43~3,44~4,45~5,46~6,47~7,24~16,25~17,26~18,27~19,28~20,29~21,30~22,31~23,48~16,49~17,50~18,51~19,52~20,53~21,54~22,55~23,56~16,57~17,58~18,59~19,60~20,61~21,62~22,63~23
cat /etc/rc.local.inc
QNUM=16
for phys_iface in $(ls /sys/class/net | grep -P "^eth\d+$")
do
echo Setting combined queue to $QNUM on $phys_iface ...
ethtool -L $phys_iface combined $QNUM
done
cat /etc/modprobe.d/vpndrvr.conf | grep cpu_distribution
options vpndrvr cpu_distribution=*:#0,1,2,3,4,5,6,7,16,17,18,19,20,21,22,23/#8~0,9~1,10~2,11~3,12~4,13~5,14~6,15~7,32~0,33~1,34~2,35~3,36~4,37~5,38~6,39~7,40~0,41~1,42~2,43~3,44~4,45~5,46~6,47~7,24~16,25~17,26~18,27~19,28~20,29~21,30~22,31~23,48~16,49~17,50~18,51~19,52~20,53~21,54~22,55~23,56~16,57~17,58~18,59~19,60~20,61~21,62~22,63~23
cat /etc/rc.local.inc
QNUM=16
for phys_iface in $(ls /sys/class/net | grep -P "^eth\d+$")
do
echo Setting combined queue to $QNUM on $phys_iface ...
ethtool -L $phys_iface combined $QNUM
done
cat /opt/l2svc/etc/global.cfg
...
L2VPN_CORE_COUNT="16"
BOND_MODE="balance-xor"
BOND_MIIMON="100"
BOND_XMIT_HASH_POLICY="layer2+3"
...
cat /etc/modprobe.d/vpndrvr.conf | grep cpu_distribution
options vpndrvr cpu_distribution= *:#0,1,2,3,4,5,6,7,16,17,18,19,20,21,22,23/#8~0,9~1,10~2,11~3,12~4,13~5,14~6,15~7,32~0,33~1,34~2,35~3,36~4,37~5,38~6,39~7,40~0,41~1,42~2,43~3,44~4,45~5,46~6,47~7,24~16,25~17,26~18,27~19,28~20,29~21,30~22,31~23,48~16,49~17,50~18,51~19,52~20,53~21,54~22,55~23,56~16,57~17,58~18,59~19,60~20,61~21,62~22,63~23
cat /etc/rc.local.inc
QNUM=16
for phys_iface in $(ls /sys/class/net | grep -P "^eth\d+$")
do
echo Setting combined queue to $QNUM on $phys_iface ...
ethtool -L $phys_iface combined $QNUM
done